
type
status
date
slug
summary
tags
category
icon
password
Redis的数据已经设置了TTL,不是过期就已经删除了吗?为什么还存在所谓的淘汰策略呢?这个原因我们需要从redis的过期策略聊起。
过期策略
定期删除
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。
Redis 默认会每秒进行十次过期扫描(100ms一次),过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
1.从过期字典中随机 20 个 key;
2.删除这 20 个 key 中已经过期的 key;
3.如果过期的 key 比率超过 1/4,那就重复步骤 1;
redis默认是每隔 100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载。
惰性删除
所谓惰性策略就是在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除,不会给你返回任何东西。
定期删除可能会导致很多过期key到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,即当你主动去查过期的key时,如果发现key过期了,就立即进行删除,不返回任何东西.
总结:定期删除是集中处理,惰性删除是零散处理。
更多阅览
介绍:这是一本完整的阐述分布式应用系统架构设计及实践的数据,既有基础,也有实践,主要如下:
基础层面:全书通过完整的基础技术介绍,为读者充分阅读和理解后续的架构实践提供扎实的技术基础,例如常见中间件的技术原理、高性能、高可用、可伸缩的常见实现方案等。另外还有高可用场景下的多机房多活如何实现,数据如何保持全局的一致性等问题也会有详细讨论。
架构实践层面:全书通过几个完整的案例来阐述具体在分布式架构中的实际问题以及解决方案,例如账号系统下的会话粘连保持、数据一致性、以及实现安全的数据降级;以及秒杀系统下的流量金字塔优化、热点账户的冲扣性能优化以及扣款场景下的数据一致性问题等等这些在书中都会有详细介绍以及。
为什么需要淘汰策略
有了以上过期策略的说明后,就很容易理解为什么需要淘汰策略了,因为不管是定期采样删除还是惰性删除都不是一种完全精准的删除,就还是会存在key没有被删除掉的场景,所以就需要内存淘汰策略进行补充。
内存淘汰策略
1. noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
2. allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
3. volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
4. allkeys-random:加入键的时候如果过限,从所有key随机删除
5. volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
6. volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
7. volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
8. allkeys-lfu:从所有键中驱逐使用频率最少的键
LRU
标准LRU实现方式
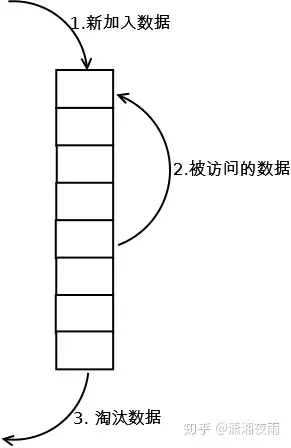
1. 新增key value的时候首先在链表结尾添加Node节点,如果超过LRU设置的阈值就淘汰队头的节点并删除掉HashMap中对应的节点。
2. 修改key对应的值的时候先修改对应的Node中的值,然后把Node节点移动队尾。
3. 访问key对应的值的时候把访问的Node节点移动到队尾即可。
Redis的LRU实现
Redis维护了一个24位时钟,可以简单理解为当前系统的时间戳,每隔一定时间会更新这个时钟。每个key对象内部同样维护了一个24位的时钟,当新增key对象的时候会把系统的时钟赋值到这个内部对象时钟。比如我现在要进行LRU,那么首先拿到当前的全局时钟,然后再找到内部时钟与全局时钟距离时间最久的(差最大)进行淘汰,这里值得注意的是全局时钟只有24位,按秒为单位来表示才能存储194天,所以可能会出现key的时钟大于全局时钟的情况,如果这种情况出现那么就两个相加而不是相减来求最久的key。
struct redisServer {
pid_t pid;
char *configfile;
//全局时钟
unsigned lruclock:LRU_BITS;
...
};
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
/* key对象内部时钟 */unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;Redis中的LRU与常规的LRU实现并不相同,常规LRU会准确的淘汰掉队头的元素,但是Redis的LRU并不维护队列,只是根据配置的策略要么从所有的key中随机选择N个(N可以配置)要么从所有的设置了过期时间的key中选出N个键,然后再从这N个键中选出最久没有使用的一个key进行淘汰。
下图是常规LRU淘汰策略与Redis随机样本取一键淘汰策略的对比,浅灰色表示已经删除的键,深灰色表示没有被删除的键,绿色表示新加入的键,越往上表示键加入的时间越久。从图中可以看出,在redis 3中,设置样本数为10的时候能够很准确的淘汰掉最久没有使用的键,与常规LRU基本持平。
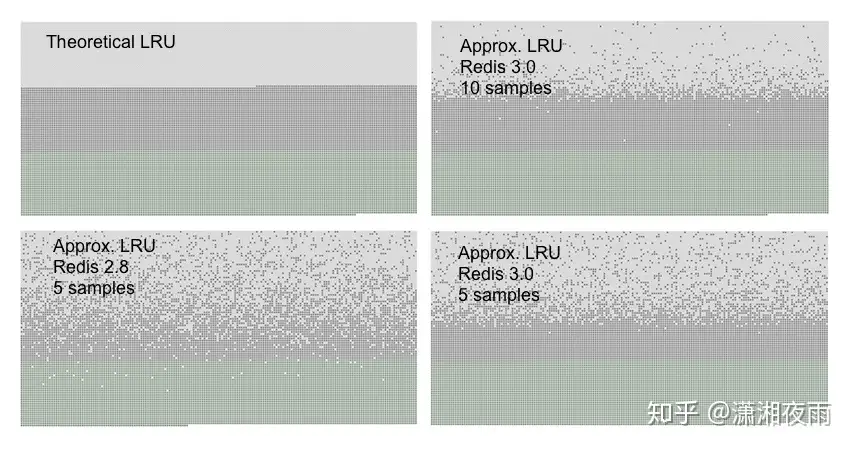
为什么要使用近似LRU?
1、性能问题,由于近似LRU算法只是最多随机采样N个key并对其进行排序,如果精准需要对所有key进行排序,这样近似LRU性能更高
2、内存占用问题,redis对内存要求很高,会尽量降低内存使用率,如果是抽样排序可以有效降低内存的占用
3、实际效果基本相等,如果请求符合长尾法则,那么真实LRU与Redis LRU之间表现基本无差异
4、在近似情况下提供可自配置的取样率来提升精准度,例如通过 CONFIG SET maxmemory-samples <count> 指令可以设置取样数,取样数越高越精准,如果你的CPU和内存有足够,可以提高取样数看命中率来探测最佳的采样比例。
LFU
LFU是在Redis4.0后出现的,LRU的最近最少使用实际上并不精确,考虑下面的情况,如果在|处删除,那么A距离的时间最久,但实际上A的使用频率要比B频繁,所以合理的淘汰策略应该是淘汰B。LFU就是为应对这种情况而生的。
A~~A~~A~~A~~A~~A~~A~~A~~A~~A~~~|
B~~~~~B~~~~~B~~~~~B~~~~~~~~~~~~B|
LFU把原来的key对象的内部时钟的24位分成两部分,前16位还代表时钟,后8位代表一个计数器。16位的情况下如果还按照秒为单位就会导致不够用,所以一般这里以时钟为单位。而后8位表示当前key对象的访问频率,8位只能代表255,但是redis并没有采用线性上升的方式,而是通过一个复杂的公式,通过配置如下两个参数来调整数据的递增速度。
lfu-log-factor 可以调整计数器counter的增长速度,lfu-log-factor越大,counter增长的越慢。
lfu-decay-time 是一个以分钟为单位的数值,可以调整counter的减少速度。
所以这两个因素就对应到了LFU的Counter减少策略和增长策略,它们实现逻辑分别如下。
降低LFUDecrAndReturn
1、先从高16位获取最近的降低时间ldt以及低8位的计数器counter值
2、计算当前时间now与ldt的差值(now-ldt),当ldt大于now时,那说明是过了一个周期,按照65535-ldt+now计算(16位一个周期最大65535)
3、使用第2步计算的差值除以lfu_decay_time,即LFUTimeElapsed(ldt) / server.lfu_decay_time,已过去n个lfu_decay_time,则将counter减少n。
增长LFULogIncr
1、获取0-1的随机数r
2、计算0-1之间的控制因子p,它的计算逻辑如下
//LFU_INIT_VAL默认为5
baseval = counter - LFU_INIT_VAL;
//计算控制因子
p = 1.0/(baseval*lfu_log_factor+1);3、如果r小于p,counter增长1
p取决于当前counter值与lfu_log_factor因子,counter值与lfu_log_factor因子越大,p越小,r小于p的概率也越小,counter增长的概率也就越小。增长情况如下图:
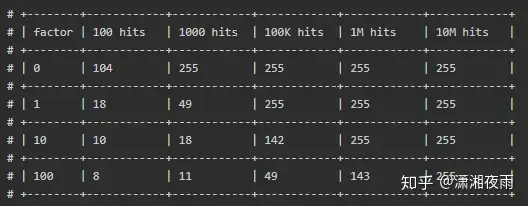
从左到右表示key的命中次数,从上到下表示影响因子,在影响因子为100的条件下,经过10M次命中才能把后8位值加满到255.
新生KEY策略
另外一个问题是,当创建新对象的时候,对象的counter如果为0,很容易就会被淘汰掉,还需要为新生key设置一个初始counter。counter会被初始化为LFU_INIT_VAL,默认5。
- Author:NotionNext
- URL:https://tangly1024.com/article/ec81f1e7-13ef-4789-ba3d-5d0e2d479b0a
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!